Managing Network Security
Risk Staging
by Fred Cohen
Series Introduction
Over the last several years, computing has changed to an almost purely
networked environment, but the technical aspects of information protection
have not kept up. As a result, the success of information security programs
has increasingly become a function of our ability to make prudent management
decisions about organizational activities. Managing Network Security takes
a management view of protection and seeks to reconcile the need for security
with the limitations of technology.
Introduction:
It is almost
never feasible to prevent all of the harmful things that can happen to an
information system, and it is rarely cost effective to do so. But if we
don't prevent harm, we will almost certainly take some damage. When we
encounter harmful events, we typically respond to them in one form or
another depending on the damage we have and expect to suffer. The question
arises of how we decide when to prevent, detect, and react. This is the
issue of risk staging.
An understanding of two dimensions of the
risk-staging problem has been particularly helpful in my work.
For now, I will call them the static and dynamic cases. The static
risk-staging problem starts with the assumption that everything is
steady state, a condition that never actually exists in information
technology today, but that can be used to think about how to balance
approaches. The dynamic risk-staging problem addresses when risk
mitigation should be completed, or in the more detailed case, how
to sequence the implementation of risk mitigation activities.
You can't react unless you can detect:
In 1997, I did a national technical baseline study of
intrusion detection and response. In the process, I reviewed more than 350
papers on the subject, talked to scores of researchers and developers as
well as many users of these systems, and tried several of these systems out.
If there is one thing I gleaned from the past 15 years of scientific
research into intrusion detection and response, it is that we cant detect
many of the harmful things that happen to information systems.
At a theoretical level the problem is, of course,
undecidable. No matter how many things we are able to detect, there will
either be an infinite number of false positives (detected incidents that do
not correspond to actual incidents), an infinite number of false negatives
(actual incidents that are not detected), or both. Interestingly, there is a
tradeoff between false positives and false negatives that, in some systems,
can be explicitly tuned.
At a practical level, false positives stress the human
systems that investigate incidents. At some fairly low level of activity (in
comparison with the levels of false positives that can be generated by
automated systems) human response systems are unable to pick the signal out
from the noise. People adapt by ignoring incidents or by performing poorly
against them, they get cognitive overload, and they often get frustrated and
refuse to continue their efforts. The cost of handling incidents goes up
with the total number of detected indicators as well as the number of
accurate indicators.
Since false positives carry a substantial cost, many
organizations choose to minimize them. But if you minimize false positives,
the inevitable result is a lot of false negatives. And this translates into
undetected incidents ... sort of.
When to prevent:
Prevention is expensive and almost always unnecessary.
When I say unnecessary, I mean it in a specific way. It turns out that there
are a large number of ways to attack systems. Unless the number of actual
attacks against a system is very large, the vast majority of attack
mechanisms will never be used. Thus the vast majority of the prevention is
never exercised. This would not be true if we could predict which attacks
were going to be used against which systems with what frequency.
Probabilistic risk assessment (PRA) is based on the notion that we can do
that, but in my experience, the predictive power of PRA in information
protection is inadequate to change this situation. Effective prevention
almost always carries high cost and unnecessary restriction.
Because detection and reaction delay spending money on
protection until it is needed, management often chooses it. Unless you can
show that prevention is more cost effective, detection and reaction will
normally be the defenses of choice.
If we could detect attacks and react to them quickly
enough, we could, in theory at least, eliminate prevention completely. Since
we cannot detect and react accurately and quickly enough for all situations,
in those situations, protection requires prevention. But this begs the issue
of what requires protection? In order to understand this issue, we have to
talk about what causes risk.
What Causes Risk:
I will almost certainly repeat what I am about to
describe again and again, but since this is the first article in this
series, I will be a little bit more elaborate in this exposition than in the
future.
I have an equation:
DxVxT=R
Managing risk requires that we be able to define and
understand risk. My equation is intended to describe the notion that risk is
produced by a combination of dependencies, vulnerabilities, and threats. To
clarify, I usually give three examples.
- If we had a highly vulnerable system and thousands of
people who had good reason to attack it, but its failure had no impact on
our business, there would be no risk and thus no financially justified
reason to protect it.
- Similarly, if the system were critical to our
business, had no vulnerabilities, but there were thousands of attackers
anxious to attack it, there would still be no risk and thus no reason to
protect it.
- Finally, if the system was critical to our business,
was full of vulnerabilities, but there was nobody interested in attacking
it, there would be no risk and thus no reason to protect it.
In order to justify protection, we must have a risk. But
the issue runs a bit deeper than just this. The investment in risk
mitigation must have a return that, after taking all of the uncertainty into
account, meets or exceeds the return on investment I would get from
investing in other ways. This return on investment (ROI) perspective on
protection requires that we be able to clearly demonstrate the risks in
terms of financial impacts. A clear demonstration, at least for most
business people I know, requires some data from real incidents.
Fortunately, most organizations can supply that sort of
data if they only look for it. An example might help. In one organization I
work with, macro viruses had become a substantial issue. In encountering one
on a PC, I asked about it and was told by the technician who came to clean
it up that most people in the support organization spend an average of a few
hours a day cleaning up after computer viruses. I later went to a meeting of
the support group and asked for confirmation of that figure, and sure
enough, something like 20 percent of the time spent on support ended up
spent removing macro viruses from systems. Furthermore, all of these macro
viruses were spreading via email attachments.
I did a quick calculation and figured out that the cost
of response was now on the order of $200,000 per year for this site - and
this didn't include lost time or data by users. I asked if they had
considered getting a central virus scanner for their email server. They
indicated that such a system carried a cost of $50,000 and required
substantial time and effort to maintain (about $50,000 per year). My report
indicated that an ROI of 2 to 1 could be attained in the first year and that
in subsequent years the return would be on the order of 4 to 1. This wasn't
a speculation based on some combination of guesses about statistical
phenomena. It was based on clear empirical evidence gathered from their own
experience.
Translating this result into the DxVxT equation is
neither easy to do nor particularly important once we have an ROI to
report. Clearly we have a case where a relatively modest investment bears
very good returns with almost no guesswork and in a very short time. This is
also a case where detection and response (macro viruses are detected in the
server and removed) are automated so that they, in effect, become
prevention. It is thus also a case where risk staging favors prevention over
detection and response and where analysis can clearly show the rationality
of this choice. Nevertheless, it may be useful to point out what the D, V,
and T components are in this case.
Dependencies: The systems being infected by
viruses in these cases are used for normal business purposes. They
facilitate communication between individuals within the organization and
individuals in customer and vendor organizations. While the business can
exist without these systems, they provide far greater efficiency than can be
attained through other means. Timeliness is not usually critical in these
systems. The dependencies have been demonstrated by actual harm.
Vulnerabilities: These systems are vulnerable to
all sorts of attacks, but the particular vulnerability here is from macro
viruses. All of these systems are vulnerable and none of the vulnerabilities
can be removed today without destroying the utility of the systems. The
vulnerabilities have been demonstrated by exploitations against this
organization.
Threats: The threats range over a wide range. Very
little skill is required in order to write computer viruses and this
organization is targeted and actively attacked by threats with the
motivation and capability to use viruses. This has been demonstrated by
actual incidents.
Static Risk Staging Summary:
To summarize results on the static risk staging
challenge, I have the following word equation.
Prevent when [[time and accuracy limitations of detection
and reaction mandate it] OR [it is more cost effective than alternatives]]
AND the risk reduction (read DxVxT-D'xV'xT') yields adequate return on
investment.
Dynamic Risk Staging:
Several years ago, Ron Knecht (a very knowledgeable and
thoughtful expert in this field) asked me what would seem to be a very
simple question. He wanted to know when we should expect to achieve our
national infrastructure protection goals. In trying to answer his question,
I came to understand some things about dynamic risk staging.
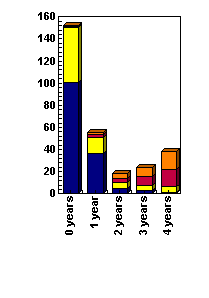
|
The basic issue I addressed in dynamic risk staging
was the financial effect of trying to achieve a desired level of
protection in different time frames. The plot here shows an analysis
of the cost of improving protection in a particular computing
environment verses the time protection is fully in place. The general
shapes of the curves are valid in many cases. In particular, I found
four factors that were involved in risk staging.
- lifecycle location (blue)
- acquisition costs (yellow)
- attack losses (orange)
- lost opportunities (red)
|
Lifecycle location costs come from the fact that
modifications to systems cost more and more as we move from the beginning of
the lifecycle toward the end. If we try to retrofit protection into all of
our existing systems, the cost will be very high.
Acquisition costs come from both the acquisition cycle
and the development of new technologies. Trying to buy the latest and
greatest technologies on almost no notice makes the acquisition process far
more expensive. Waiting even one year has a very substantial impact on the
cost of a technology as well as on the ability to bargain for a better
price.
The cost of attacks is cumulative and tends to increase
over time. If effective protection is in place at a given time, subsequent
losses from attacks will be within the managed level of risk, so delaying
implementation tends to increase loss. The times here can be quite short for
some situations. In some cases, within a few hours after an attack is
announced it is exploited in thousands of systems.
Lost opportunity comes in the form of the inability to
use technology for activities that would be very risky without proper
protection in place. For example, Internet commerce has very high potential
risks if protection is not in place. Thus, for deciding about how to stage
Internet protection, lost opportunity may far outweigh acquisition costs
over time frames as short as a few months.
Combined Results:
In most environments, static and dynamic risk staging are
combined to form a mix of current and planned protective measures.
Prevention strategies that may work in 3 years might be covered by detection
and response capabilities in the short run, while in other cases, short term
risk-taking might be used in anticipation of improved technologies for
mitigating a particular risk in the coming years.
In order to do a really good job of risk staging,
optimization techniques can be used. One technique for accomplishing this is
by using a graph analysis to select the best sequence of prevention,
detection, and response options implemented in sequence over time. But this
sort of optimization is beyond the scope of this article.
Conclusions:
Risk staging is an important protection management
technique that has not been widely studied in the literature. It can be
effectively used to trade off resources and it is implicit in many decisions
about protection. The static risk staging process is, in effect, used every
time the decision is taken to not use prevention. They dynamic risk staging
technique is used every time we decide to delay implementation. In making
these explicit and beginning to study them, I hope to accomplish two things.
One is to find new ways to address protection. The other is to encourage
others to take up the subject and produce the sorts of results we all need
to make protection more effective.
About The Author:
Fred Cohen is a Principal Member of Technical Staff at Sandia National
Laboratories and a Managing Director of Fred Cohen and Associates in
Livermore California, an executive consulting and education group
specializing information protection. He can be reached by sending email to
fred at all.net or visiting /