
Figure 1 - The Structure of Defensive Network Deception
In the last year, deception has emerged as one of the emerging techniques for effective information protection [Cohen98] [Drill-Down] in networks. A natural side effect of the use of this technology is the desire to understand the mathematical properties underlying its utility. In the above cited paper, several informal notions were introduced - to wit:
In this paper, we will examine these claims and provide a more mathematical foundation for this aspect of deception as a tool for network defense.
There are an unlimited number of ways that deception may be used for defense. Our analysis is primarily focussed on the information theoretic notion of altering the information content [Shannon48] [Overview Drill Down] gained by intelligence efforts and the workload [Shannon49] [Overview Drill Down] associated with attacking and defending systems. These notions are somewhat different for deception than for cryptography, but conceptually, they are quite similar.
Underlying the notion of using deception for network defense is the model of an enemy who believes that information systems are vulnerable and has finite resources with which to attack them. This model would seem to imply an attack process whereby an intelligence effort is used to try to find vulnerabilities and a technical capability is used to try to exploit the vulnerabilities identified by the intelligence effort.
Even if there were a perfect defense in place, which most experts believe to be impossible, the perception of the enemy that imperfections exist and that their exploitation can affect the outcome of the conflict is key to the notion of the enemy attempting attacks. If the enemy does not believe there is an exploitable weakness, no attack will be forthcoming. Thus, we have the potential for a deception that induces the belief in the enemy that there exists and exploitable weakness of value. The goal of this deception would then be to trick the enemy into misallocating resources.
Today, the reality is that there are such weaknesses in every system of value, and all parties believe this to be the case, so the next level of deception is to try to defeat the enemy's attack process. Assuming that the enemy is technically competent and that there are real vulnerabilities, the proper identification of those vulnerabilities by the enemy's intelligence effort will yield a successful attack. Thus, the defensive deception process is and must be oriented toward defeating the enemy's intelligence process. Other aspects of the defense process, such as prevention techniques, are oriented toward eliminating the technical vulnerabilities, the ability of the enemy to exploit them, or their impacts.
Figure 1 shows the basic structure of deceptive defense. There are a potentially infinite number of possible attack techniques, and the enemy intelligence effort is directed toward finding a sequence of techniques that will be effective at achieving their goals. The defender's objectives are not necessarily at odds with this, in that the defender's strategic defense needs may not conflict with the enemy's strategic attack needs. We are thus not in a 'zero sum game'. Nevertheless, we will assume for the purposes of our discussion that the objective of the defender is to defeat the attacker's intelligence process without undue consumption of defensive resources. In other terms, the goals are to:
Given an initial set of beliefs about the defender's system, the goal of the attacker's intelligence effort is to reduce the uncertainty about what is present in the defender's systems to the point where technical attack has a high likelihood of achieving success. This is Shannon's notion of increasing information content directed toward the defender's systems. The ideal deceptive defense allows this process to proceed in such a manner that the attacker's intelligence effort appears to meet expectations without being too easy or in any other way tipping the attacker's hat. In other words, the attacker moves toward increased certainty at an appropriate rate, but the content the attacker achieves is to the defender's advantage. Over the long run, the successful defense will induce the attacker to believe that the technical attacks were successful and that some other circumstance was the cause of the ultimate failure of the overall strategy.
A classic example of a successful defense of this sort is the deception program carried out in World War II prior to the Normandy landings. In one case, British intelligence created a set of fictions surrounding the landings that fooled Hitler even after the landings took place. It was several days before he figured out that the real landings weren't a feint to cover up other landings, and by that time it was too late.
The present work is, unfortunately, not matured to the point of being able to describe this level of long-term success. For that reason, we will confine ourselves to the task of detecting each individual 'attack sequence' and making the aggregate of a large number of attack sequences unfruitful for the enemy. Thus, our goals are:
1) Make the likelihood of any individual intelligence probe encountering a real vulnerability low. This can be done by increasing the total size of the space to be searched by the intelligence effort large and by making the number of vulnerabilities in that space small. From the perspective of deceptions, only the first is attainable on the initial intelligence probe. The second is addressed in goal 4 below.
2) Make the likelihood of any individual intelligence probe encountering a deception high. This is achieved by having a large number of deceptions in the space relative to the number of vulnerabilities. The higher the ratio of deceptions to vulnerabilities, the more likely this is.
3) Make the time to defeat a deception infinite. This is done by making the deceptions extremely realistic and assuring that defeating a deception system does not provide additional undesired intelligence or paths to successful attack.
4) Make the time to detect a vulnerability once a deception is encountered from a given attack location infinite. The notion is that detecting intelligence attempts against deceptions should be very easy and that when they are encountered, further intelligence from the same source should redirect all intelligence attempts against vulnerabilities toward deceptions. The challenge with this strategy is that inconsistencies will then exist between undetected and detected intelligence efforts that might tend to reveal the real vulnerabilities.
5) Make the time to detect an intelligence probe against a deception very small. It is reasonable to assume that a deception can be designed to rapidly detect that it is being examined by an intelligence probe. In practice, technical probes have been easy to detect, however, there are certainly cases of passive intelligence probes where this is not the case.
6) Make the time to react to an intelligence probe against a deception very small. Assuming we can detect an intelligence probe and that the response can be reasonably pre-programmed, rapid reaction time is often feasible, especially against remote technical intelligence efforts.
Early 'honey pot' systems (Figure 2) were based on the idea of placing a small number of attractive targets in locations where they are likely to be found, and drawing attackers into them.
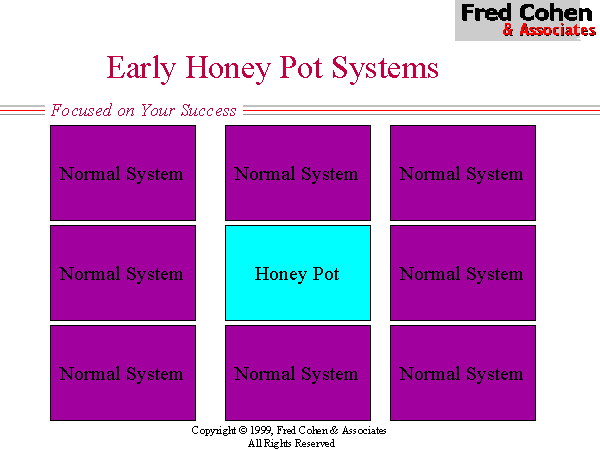
The challenge in these systems from an intelligence viewpoint is to find a way to influence the opponent to concentrate their intelligence efforts against the honey pot over other systems. This challenge is relatively easy to meet against some classes of threats, such as typical Internet-based Web site defacers who look in advertised locations for high profile systems to attack. It is also effective as a system to 'switch' an attacker to once an attack attempt has been detected. Unfortunately, for even a mildly advanced intelligence activity, this type of defense offers little in the way of effective influence because it consumes such a small portion of the overall intelligence space and has little effect on altering the characteristics of the typical intelligence probe.
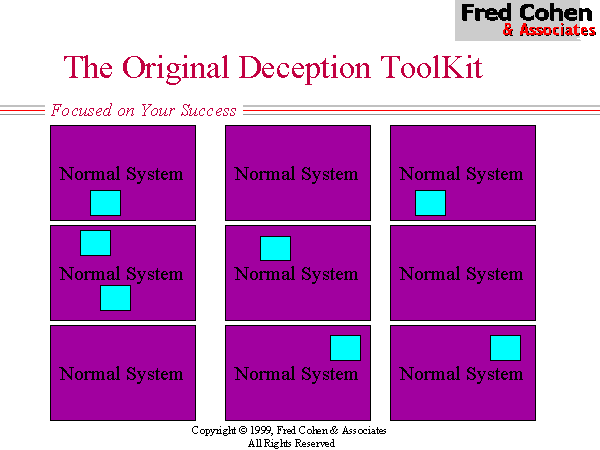
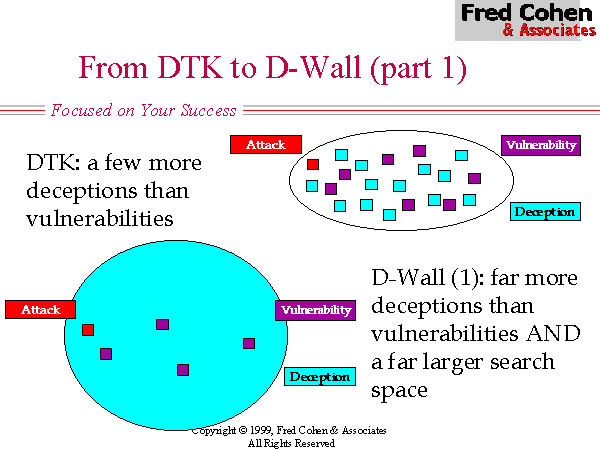
The original Deception Toolkit (DTK) provided some relief from the low probability of encountering a deception and the extreme localization of deceptions under previous honey-pot systems (see Figure 3). Under DTK, deceptions are spread among the normal systems in a network in such a way that unused services on those systems are consumed with deceptions. This has two effects. One effect is that it spreads the deceptions over a larger portion of the IP/port address space, a similar effect to Shannon's 'diffusion' used in cryptographic systems. The other effect is that increases the percentage of deceptions in the environment, thus increasing the likelihood of an intelligence probe encountering a deception rather than a vulnerability. (see Figure 4)
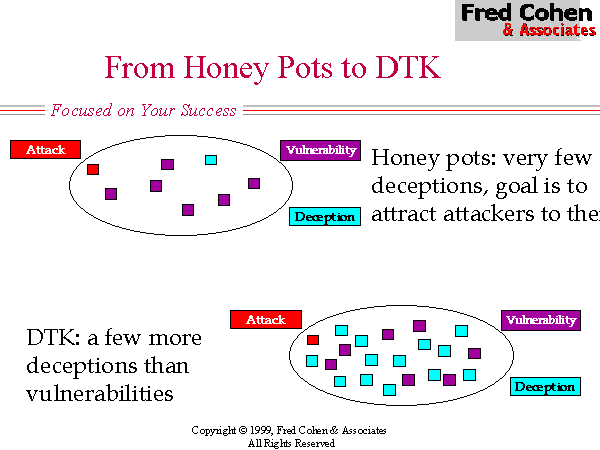
While DTK was an improvement in some sense over previous honey-pots, there are a lot of limitations in the DTK model of deception. In particular, (1) DTK had no affect on the overall search space for the intelligence effort, (2) provides only a relatively poor quality of deception, and (3) only nominally increases the sparsity of vulnerabilities in the search space. But perhaps a far more serious flaw in DTK is that it is only really effective against probes at a distance. If an attacker has gotten part of the way into a network and is willing and able to engage in observation rather than active probing, the real services will rapidly become apparent. For this reason, while DTK is effective against more of the current threats in the current environment than honey pots, it is unlikely to be effective at influencing opponent choices where that opponent has a more advanced intelligence capability.
One way to improve the situation for the defender is to increase the intelligence workload by increasing the size of the search space. This can be done in fairly trivial ways, but the results will also be fairly trivial to defeat by skilled intelligence groups. Still, any improvement 'raises the bar' for some - perhaps most - of the attackers.
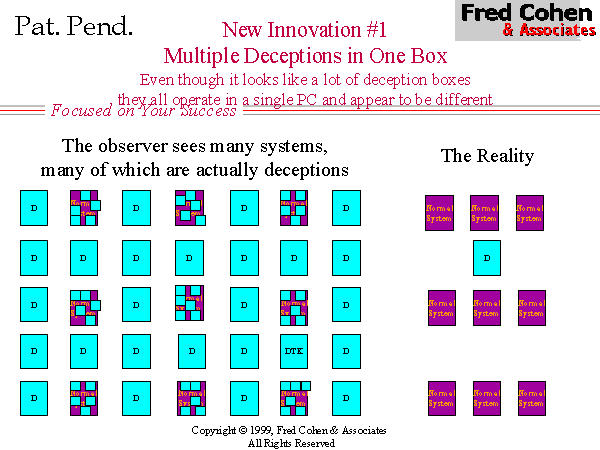
Using the multi-homed capabilities of most modern computer systems, a single Ethernet card can act as the host for numerous IP addresses, each optionally having their own MAC address as well. This technique can be applied for deception by filling a large address space that would normally be sparsely populated so that it is less sparsely populated, or perhaps even fully populated, depending on your goals and your adversary. The cost of this technique is very low. In practice, we have been able to place more than 4,000 IP addresses on a single PC running Linux, which means that with 16 $500 computer systems and about $500 worth of connecting cables and Ethernet hubs (for a total of only $8500 worth of hardware) we can do a deception that covers all of the IP addresses in a class B IP network (a.b.*.*).
Making these deceptions convincing is somewhat more complex, as we will go into a bit later, however, from a simplistic viewpoint, placing services on all of these IP addresses increases the workload of the intelligence effort in determining which of these systems are legitimate and which are not. In particular, we have used DTK to populate more than 40,000 IP addresses with false services. While the deceptions are relatively easy to spot, they are highly effective in causing the intelligence workload to go up, in increasing the time to attack, and decreasing the odds of certain classes an intelligence probes going undetected.
When a probe encounters a false service, with proper access to outside routers, we are also able to redirect all traffic into deceptions so that subsequent remote access is deception from that point forward. The conditions under which switchovers occur and what services are switched over in what conditions are held confidential because revealing them would lead to an attack in which any single known valid service that could be easily differentiated from a deception could be used to test whether the intelligence probe had been detected and responded to. The sophisticated intelligence effort would then switch to another source location and continue the search.
If we look more deeply into this feedback mechanism we can determine a level at which the IP address space is exhausted before the probability of a meaningful intelligence probe gets high enough to be of concern. This is done by the following process:
1) Set RS = the number of real services. (example 1,000) 2) Set DS = the number of deception services. (example 1,000,000) 3) Set RRD = RS/DS - the ration of real services to deceptions. (example 1/1,000 = 0.1%)
The initial probability of encountering a real service is RRD (0.1%). For each failed probe that is detected by the attacker, assume a new IP address must be used to continue probing. For each failed probe, only the specific service on the specific IP address can be eliminated from probing. This on the second try, the new value of RRD is given by RS/(DS-1). After 100,000 probes, the probability reaches RS/(DS-100,000) or (1,000/900,000) or 0.11%. Depending on various conditions, different assumptions can be made and the computation becomes more complex, but the notional result is that the resource requirement to gain meaningful intelligence via random probes is extremely high.
Of course the reason we call these things intelligence probes is that the opponent is taken to be intelligent. A more intelligent approach might be for an attacker to assume that they will first identify machines with seemingly legitimate Web servers and not search for every other service. Assuming that there are 50 such machines out of 50,000 IP addresses and that all other conditions specified above remain the same, the first probe still yields a 0.1% chance of success, but after 50,000 probes, all 50 of the legitimate web services have been identified. This is less than one attempt from every IP address in a class B network, which we know we can easily simulate using the same deception technology as the defender with only a single machine which flexes IP addresses as needed for the attack.
In the attack, countermeasure game, there is no end to the process, but we will take it a step further to give a real sense of how far we can go with this level of deception. Suppose that the defender correlated IP addresses of historical intelligence probes and, after 10 tries from different IP addresses in a class C network or 100 tries from different IP addresses in a class B network, switched the entire networks to deceptions. In this case, the probe above would be limited to 100 tries per class B network, so that in order for the attacker to identify all 50 Web servers, it would require the use of 50,000 IP addresses in 5,000 class C networks or 500 class B networks.
After determining that this sort of deception is in place, a stronger intelligence effort would not concentrate on some sort of random probing. Instead, the effort might concentrate on a more fruitful, and more expensive process, such as following existing 'known-good' paths into the infrastructure, planting insiders who can probe with far more knowledge in hand, and so forth. Countering these intelligence attempts requires a different deception advancement.
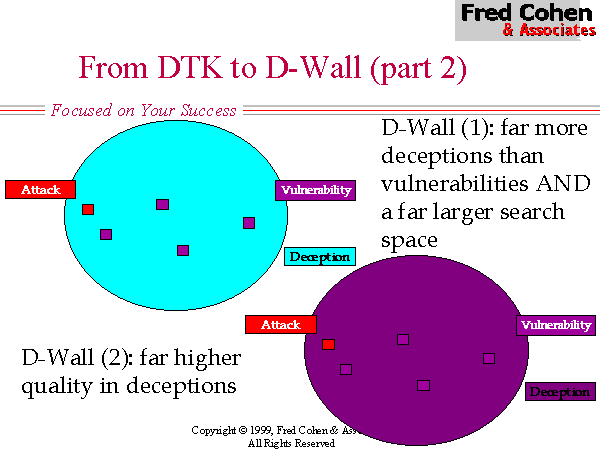
A technical advancement we have recently explored in this arena is to try to give the deceptions far higher quality so that it is very hard to differentiate a legitimate service from a deception. Some of the areas we have explored include; (1) producing simulated traffic so that traffic analysis will not be able to detect deceptions, (2) reconfiguring the deception network over time to emulate the manner in which a normal network changes over time, (3) creating organizational deceptions that support the technical deceptions, and (4) using real systems for deceptions instead of finite state machines as are used in DTK.
Simulated Traffic: We have investigated simulating traffic in the deception systems in two ways. One method is to take real traffic and reproduce it, either in real-time or in a replay mode, within the deception systems. This allows us to make one system appear to be another to the point where, in extreme cases, all access attempts are duplicated in the deception. A person within the deception network can break into a system, sniff traffic, and use the traffic to break into other systems in the deception network, without getting access to the real network, and with tracking of all of their activities. The second method is to generate traffic from (either apparently or actually) remote sites so that there is traffic that can be analyzed and exploited by an attacker. In either situation, a key to success is being able to identify the fictitious traffic somewhere in the system so as to be able to pick out the intelligence traffic from among the deceptions.
Reconfiguring the Deception Network Over Time: Real networks change over time, and if the deception is static, it will fall to long-term fairly passive intelligence efforts. One way to mitigate this is by making the deception network change over time as a real network does. In order for this to be effective, the deception characteristics should reflect the real-system characteristics as closely as possible. For example, if office computers are turned off at the end of the day, deception computers should simulate turned off machines in similar time frames. This can be done by following the behaviors of legitimate machines in near-real-time or by creating algorithms that do this. Some care is needed in that holidays, weekends, and special situations must be accounted for or any decent intelligence organization will find the deceptions quickly.
Creating Organizational Deceptions: If the organization provides access to information about individuals or systems, than the deception must somehow reflect this information as well. For example, if the DNS in your organization includes details of individual system owners and locations, you need false owners and locations to go along with your DNS tables or deceptions will be easily feretted out. Similarly, the fictitious people and locations you create will need fictitious salaries, budgets, personnel records, personal problems, bathrooms, phone numbers with people to answer them, and so on. We decided that the best move is almost always to remove the intelligence information in places like the DNS system so as to mitigate the intelligence threat at low cost while also reducing the value of these services for other forms of intelligence. A negative side effect of this is that it has an impact on network maintenance and thus a method has to be devised to allow authorized people to access this information under appropriate circumstances and with some sort of detection of attempts to abuse this access. Of course this extends the number of people who may be able to tell deceptions from real systems, and such a scheme should also be distributed to the extent possible so that even the most trusted parties only know how to tell deceptions from real systems in their own sphere of influence, and then only under supervision. Clearly, this is one of the riskiest and most complex areas of undertaking in deception, and for that reason, the alternatives of less information available to more people are far more viable than those which lead to deceptions of enormous scale. One must pick where the scale is worthwhile in exchange for some intelligence advantage and balance the advantages of the availability of information with the risks it brings.
Using Real Systems for Deceptions: Finally, the use of real systems for deceptions is a method by which we replace the simple finite state machines of DTK with live systems of the proper type. In other words, the deceptions are precisely what we assert them to be, except of course that they do not have the same content or actual functions as the machines they are designed to emulate. To make the method as sound as possible, we augment the deceptions by making the DTK-like elements of normal systems also behave through replacement systems.
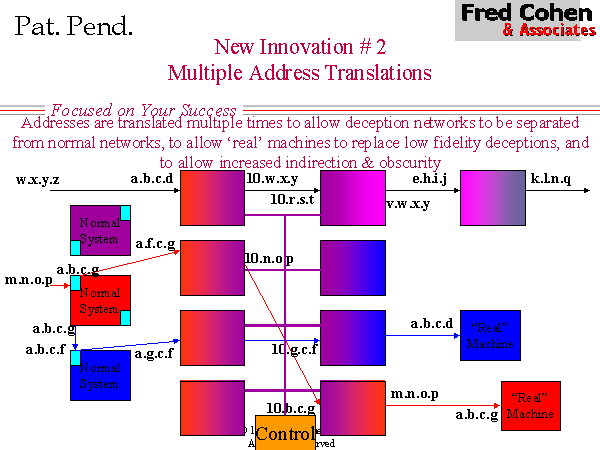
The technique shown in Figure 7 uses multiple address translation to provide the means for far higher quality in deceptions than was previously available, and does so at a very low relative cost. The basic notion is to redirect selective services - a proxy service if you will - where DTK used to handle the service directly - but rather than a simple proxy service, this service does address translation so that the same source and destination addresses remain in the deception system as were in place in the original system. In figure 7, a user from m.n.o.p enters at the interface to a.b.c.g and is redirected through a sequence of address translations to a.f.c.g which transmits from 10.n.o.p toward 10.g.c.f and finally, the last translation has the packet going from the deception version of m.n.o.p to the deception version of a.b.c.g. Another example in Figure 7 has more than two address translations (i.e., w.x.y.z eventually becomes k.l.n.q).
This mechanism can be used for a wide variety of purposes, including flexing the translation mechanisms over time for diffusion of data through multi-hop anonymizer services, tunneling traffic through intervening infrastructures, and creating multiple deceptions based on source and destinations. In the case of enhanced deception quality, we can use this method to associate deception services to the same machine type and configuration as the real services thus dramatically increasing the realism associated with the deception.
The set of techniques introduced in this paper address two major impediments to effective deception against high quality technical intelligence efforts; (1) address aliasing, and (2) multiple address translation. By combining these technological advances with a more advanced approach to deception, we can dramatically increase the complexity of the technical intelligence process against networked information systems with relatively little increase in cost.
[Cohen98-1] F. Cohen, A Note on the Role of Deception in Information Protection , Computers and Security 1999. [ This paper concentrates on the role of deception in information protection, and as such, its main focus is on addressing different perspectives on deception. We begin by examining the historical use of deception for information protection in more depth, consider the moral issues associated with the use of deception for protection, and examine techniques for deceptive defense and complexities in their use. Next we describe theoretical issues behind the use of deception in the Deception ToolKit (DTK), practical results on the use of DTK in the Internet and in an experimental environment, and notions about the widespread use of DTK and similar tools. Finally, we summarize results, draw conclusions, and discuss further work.] [Drill-Down]
[Shannon48] C. Shannon, A Mathematical Theory of Communications, Bell Systems Technical Journal. 3, no. 27, (July 1948). [This is perhaps the most famous and seminal paper in the information sciences. In this paper, Shannon described the first practical syntactic information theory, which formed the basis for a vast array of developments in the information sciences from the design of computer instruction sets to the integrity of satellite communications and beyond. It is hard to overestimate the impact of this work.] [Overview Drill Down]
[Shannon49] C. Shannon, Communications Theory of Secrecy Systems, Bell Systems Technical Journal (1949):656--715. [In this paper, Shannon applied his information theory to breaking all of the known ciphers up till that date and provided a proof that the only theoretically unbreakable cryptosystem was the so-called perfect cipher. This paper also introduced the concepts of diffusion and confusion, and introduced the concept of work load which is the basis for using imperfect cryptosystems today.] [Overview Drill Down]